高并发
- 高并发读
- 高并发写
- 高并发读写
总结:想要高并发,首先要高性能,性能工程对于性能优化是有一些原则方法论的
单个数据库每秒两三千并发就基本扛不住了
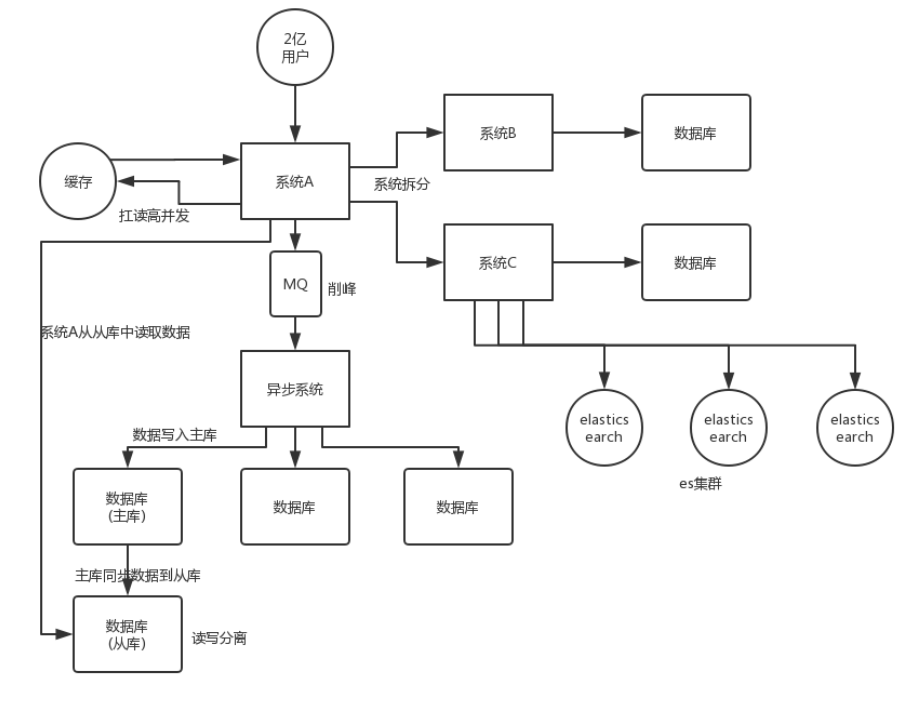
系统拆分
将单体系统拆分成多个系统或者多个服务,每个子系统使用自己的数据库,提高并发度
大部分的系统都是需要经过多轮拆分的,第一轮拆分将系统粒度划的小一点,可能随着业务的发展,单个系统会变得更复杂,所以需要进一步的拆分
拆分的维度:
- 业务维度
- 功能维度
- 资源维度 资源使用多与使用少的场景划分
局部并发原则
将同步调用的外部服务拆分为多个无关异步调用,来提升性能
高性能流程
容量规划
使用压测监控预测等确定要支撑多少性能指标 确定哪些性能指标的基准水位线
负载测试
测试系统在正常运行压力下的各项指标,这个流程是一个长期的流程以保证系统性能可预测,出现问题也能发现问题在哪
压力测试
要压到发现系统失效点,远高于正常的负载 只对关键、瓶颈业务进行测试 好钢用在刀刃上
失效点关注于响应时间、内存、失败率等异常指标
APM监控
- 基础监控:通过时序数据等指标发现异常以告警
- 追踪监控:通过链路追踪以发现出错的原因
- 业务监控
弹性扩缩容
根据监控,使用策略,管理资源
高并发读
策略:加缓存
大部分高并发的场景,都是写多读少,使用缓存,可以有效抗住高并发
对于缓存需要考虑 雪崩 击穿 穿透 等缓存问题
- 本地缓存或以Redis为代表的集中式缓存
- 数据库主从复制分担主库压力
- CDN 静态加速
策略:并发读
- 异步RPC 要求各个调用之间是独立的
- 既然数据库每秒能撑住的请求是有限的,那么就可以使用MQ,大量的请求灌入MQ,利用MQ的削峰,让下游系统慢慢消费
- 冗余请求 通过每次调用多个服务器 哪个返回的快就使用的哪个
- 分库分表 让每个表的数据少一点,提高SQL的执行速度
策略:重写轻读
某些事件产生的数据提前聚合好 等需要的时候直接读取即可 而非在需要的时候实时计算
读写分离
- 数据库读写分离
大部分对数据库的请求都是读多写少,所以读写分离,分配多一些机器给读请求,能有效提高性能
读写分离带来的问题及解决方案:
- 复制延迟
- 针对特定业务 读写都在主机上 非核心业务使用从机
- 读从机,发现从机上的数据是旧的 则二次读取主机
- 分配机制 如何让客户端将读写操作区分开来,然后访问不同的数据库服务器
- 客户端分离 TDDL shardingSphere 动态数据源也可以实现
- 数据库中间件 [MyCat](/中间件/数据库/MyCat.html), MySQL Router,
高并发写
数据分片
- 数据库[分库分表](/中间件/数据库/mysql/数据库优化.html#分库分表)
- JDK的ConcurrentHashMap 通过分段(之前的版本) 来降低竞争
- Kafka的分区 不同的分区可以并发地读写
- ES分布式索引
任务分片
- 指令流水线
- mapreduce
异步化
减少等待、Y轴扩展、削峰填谷
- 系统层面:异步网络模型
- JDK层面 NIO等
- 接口层面 线程池 异步调用 Future等
- 业务层面 RPC方式
批量
- 批量写入数据
- 将小操作合并成一整个大操作
妥协
资源是有限的 并发无上限
- 排队系统
- 基于阻塞方式
- 基于令牌方式(令牌桶)
- 熔断降级
负载均衡
调度后方的多台机器,以统一的接口对外提供服务,承担此职责的技术组件被称为“负载均衡”。
- 四层负载均衡优势是性能高,七层负载均衡的优势功能强
- 做多级混合负载均衡,通常应是低层的负载均衡在前,高层的负载均衡在后
“四层”的意思是说这些工作模式的共同特点是都维持着同一个TCP连接,而不是说它就只工作在第四层
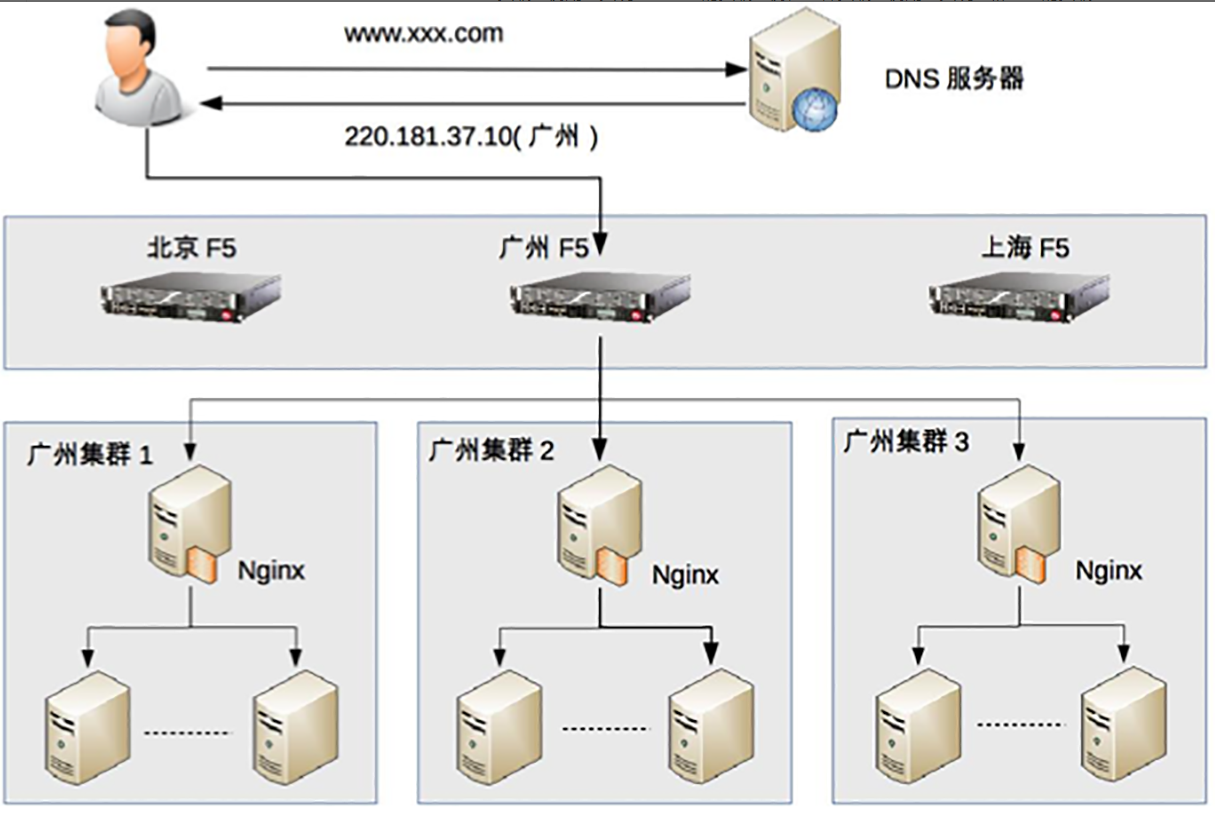
链路负载均衡
通过DNS解析来完成,每次 DNS 解析的结果都会在几个 IP 地址之间进行轮询,从而实现负载均衡。优点是可以返回离用户地理位置更近的服务器,缺点是DNS具有多级结构,DNS解析结果可能被各级缓存,修改DNS记录后,需要比较长的时间才能生效。大型网站基本使用了 DNS 做为第一级负载均衡手段,然后在内部使用其它方式做第二级负载均衡
硬件负载均衡
- F5 A10 等能支持达到百万量级的并发 缺点就是贵
操作系统负载均衡
利用系统级别的中断以及多队列网卡等来充分利用资源 达到负载均衡的功能
客户端负载均衡
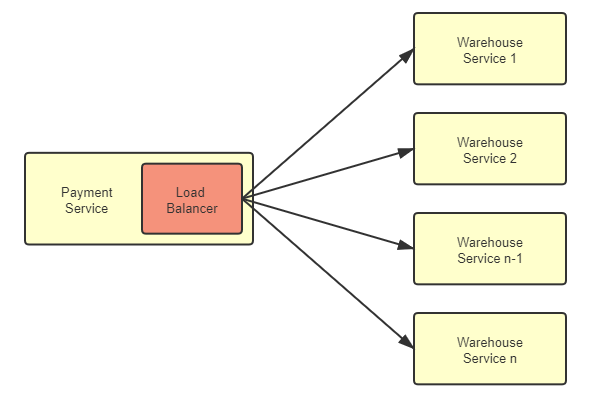
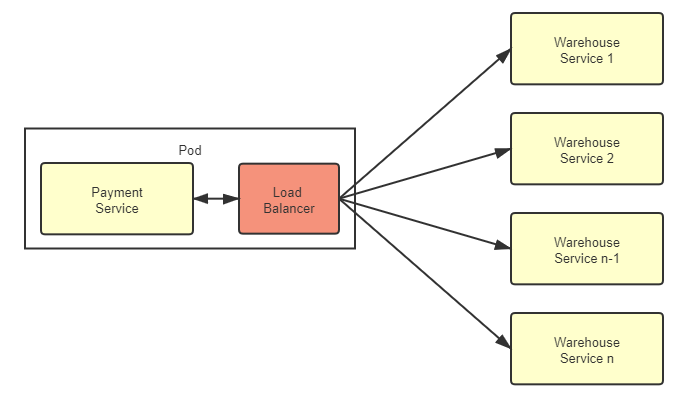
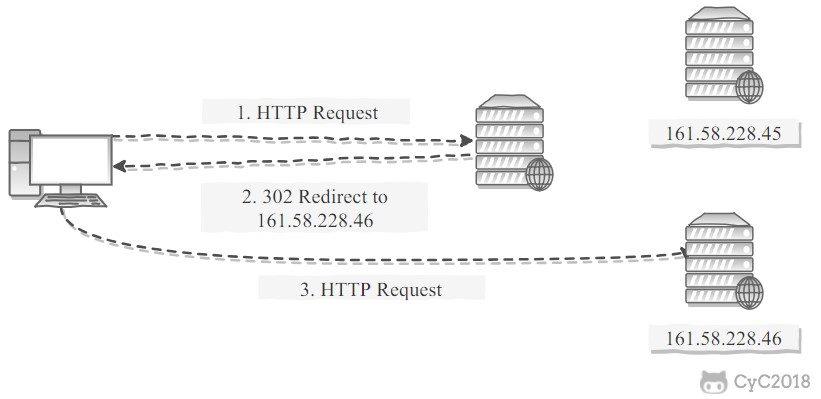
HTTP负载均衡
负载均衡服务器使用某种负载均衡算法计算得到服务器的 IP 地址之后,将该地址写入 HTTP 重定向报文中,状态码为 302。客户端收到重定向报文之后,需要重新向服务器发起请求
这样客户端需要两次请求,性能会受到一定影响
集群负载均衡
网络级别的负载均衡
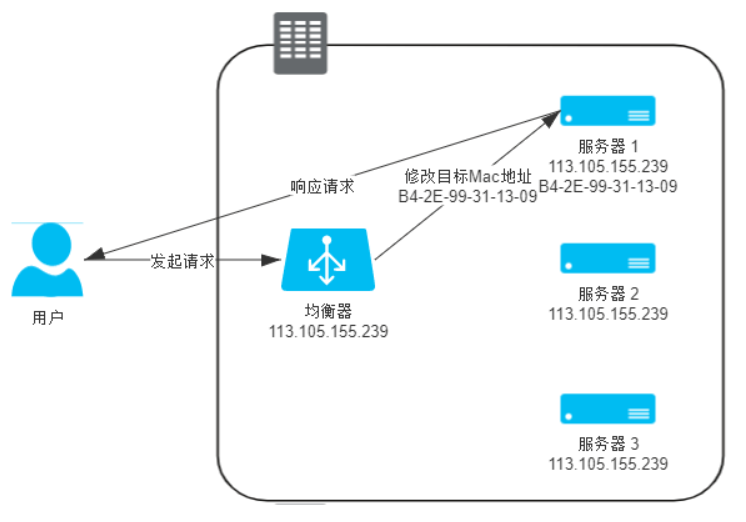
直接修改请求的数据帧中的MAC目标地址,让用户原本是发送给负载均衡器的请求的数据帧,被二层交换机根据新的MAC目标地址转发到服务器集群中对应的服务器,二层负载均衡器直接改写目标MAC地址的工作原理决定了它与真实的服务器的通讯必须是二层可达的。效率很高 网络层负载均衡:
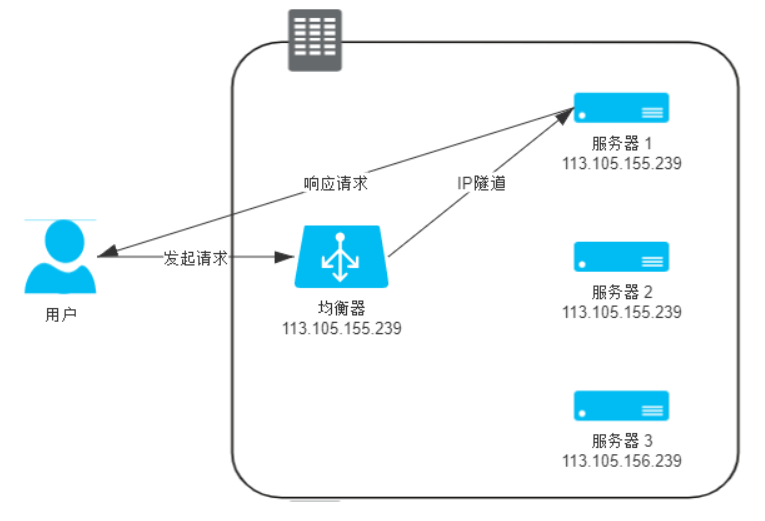
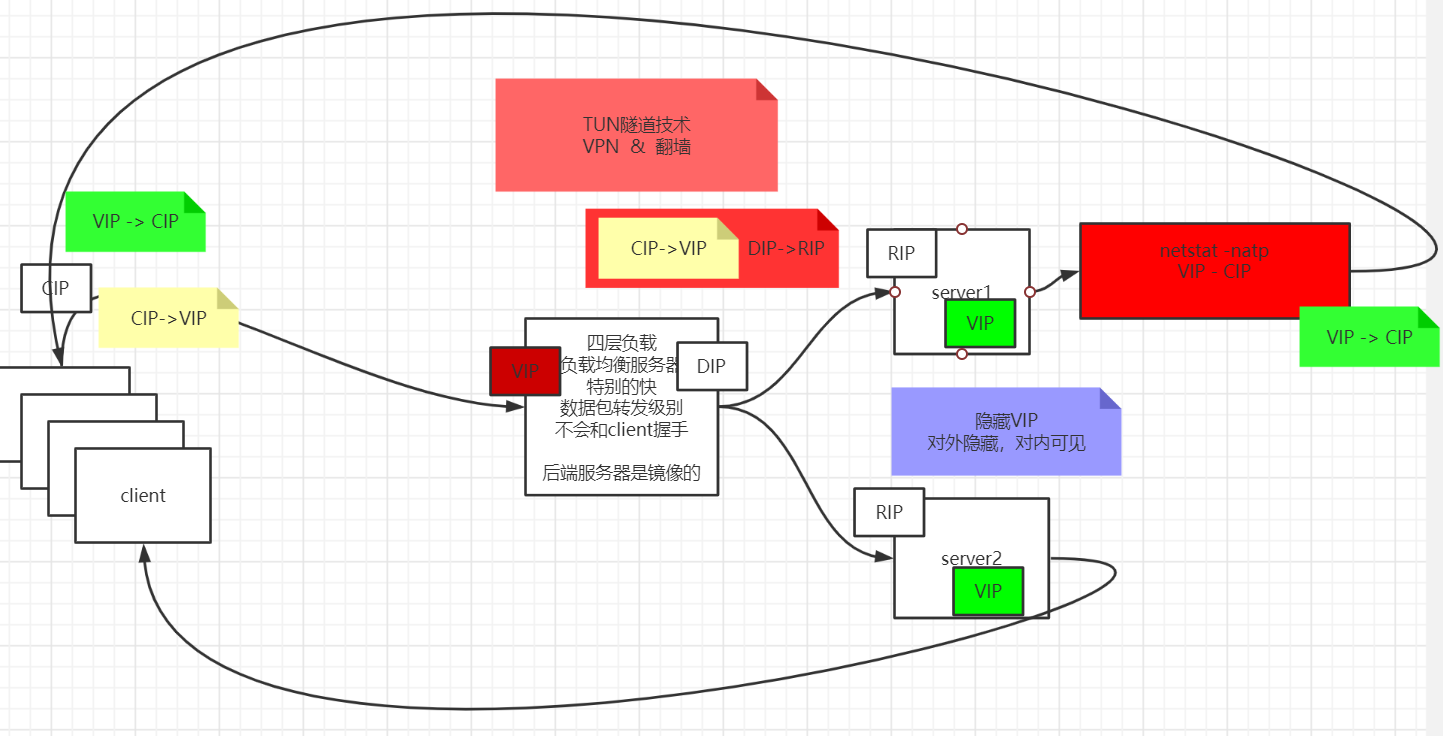
对IP包进行封装,封装成一个新包发送到后端服务器,这种方式需要后端服务器持有一个VIP 这样才能直接响应请求,不够透明
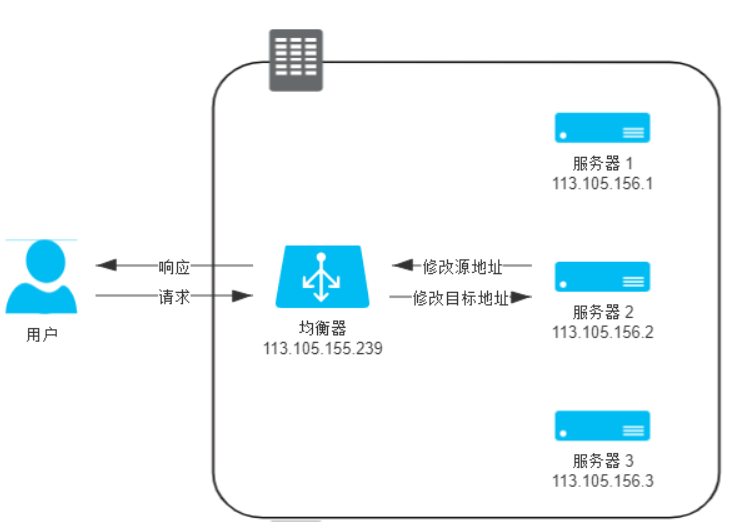
直接由均衡器对IP头进行修改 所有数据报都要经过均衡器,这个均衡器很容易称为瓶颈 更彻底的NAT模式:均衡器在转发时,不仅修改目标IP地址,连源IP地址也一起改了,源地址就改成均衡器自己的IP,称作Source NAT(SNAT),在后端服务器的视角看来,所有的流量都来自于负载均衡器
应用层负载均衡:
该层的优势就在于比链路层 网络层可以得到更多的信息 从而做出更加智能的决策
负载均衡算法
任务平分类
- 轮循均衡
- 权重轮循均衡
- 随机均衡
- 权重随机均衡
压力均衡类
- 响应速度均衡
- 最少连接数均衡
hash类
- 一致性哈希均衡
- ip哈希
- id哈希
均衡器实现
- 硬件负载均衡 F5 A10
- 软件负载均衡
- 构建在内核的:LVS
- 应用程序的形式:Nginx、HAProxy、KeepAlived
- 构建在内核的:LVS
LVS
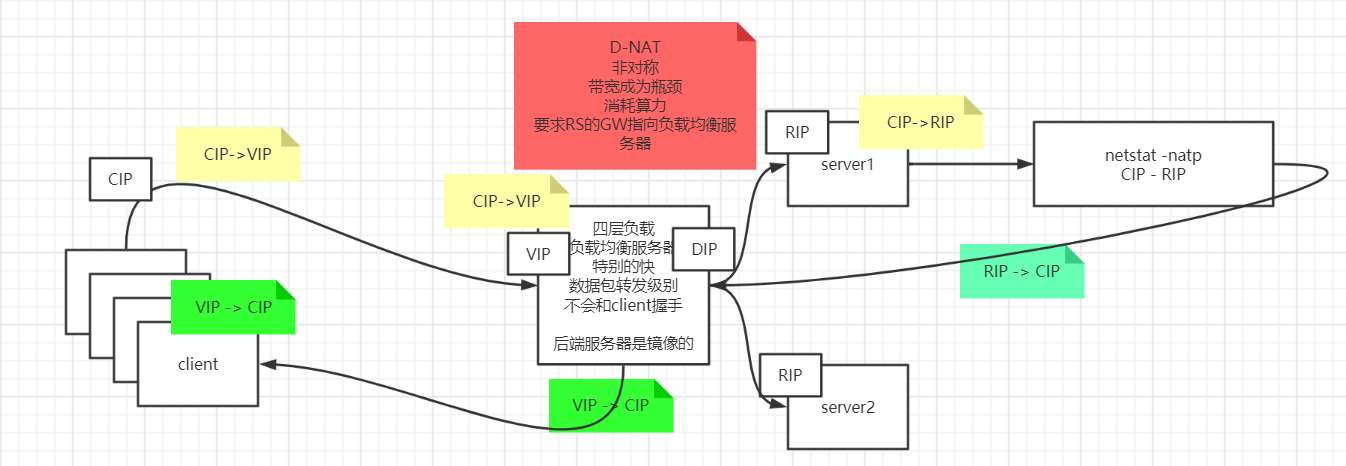
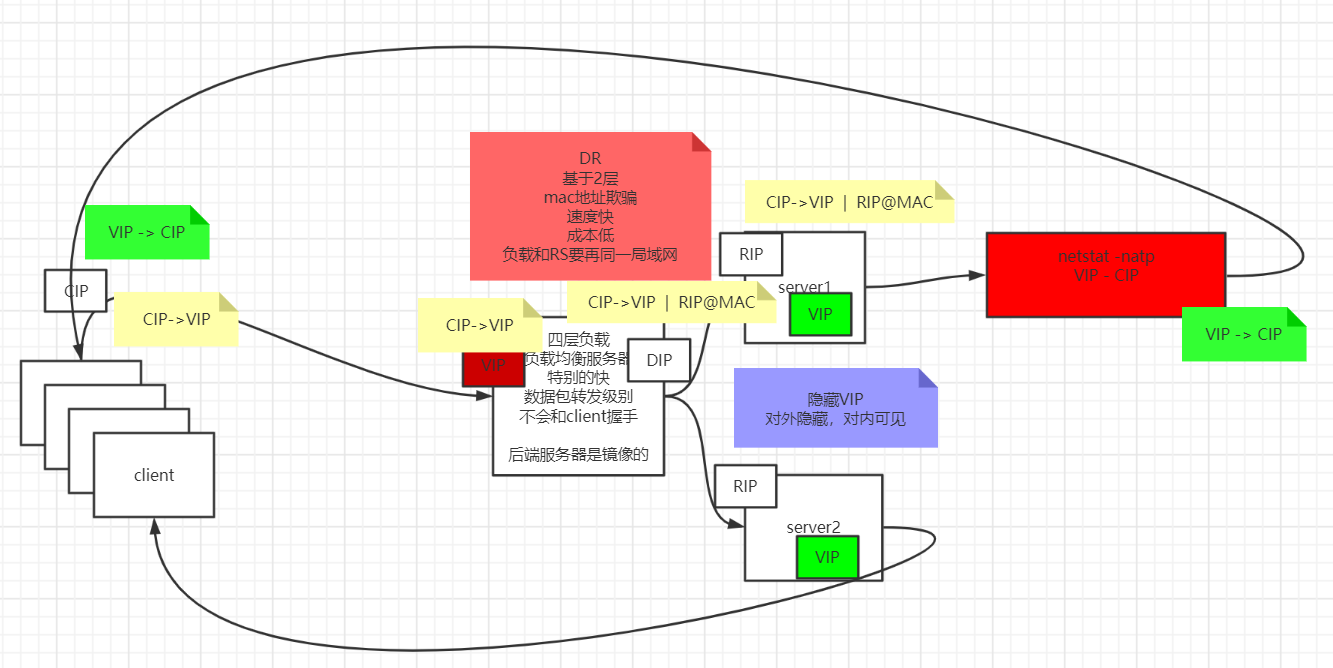
将RS的VIP配置在内核中
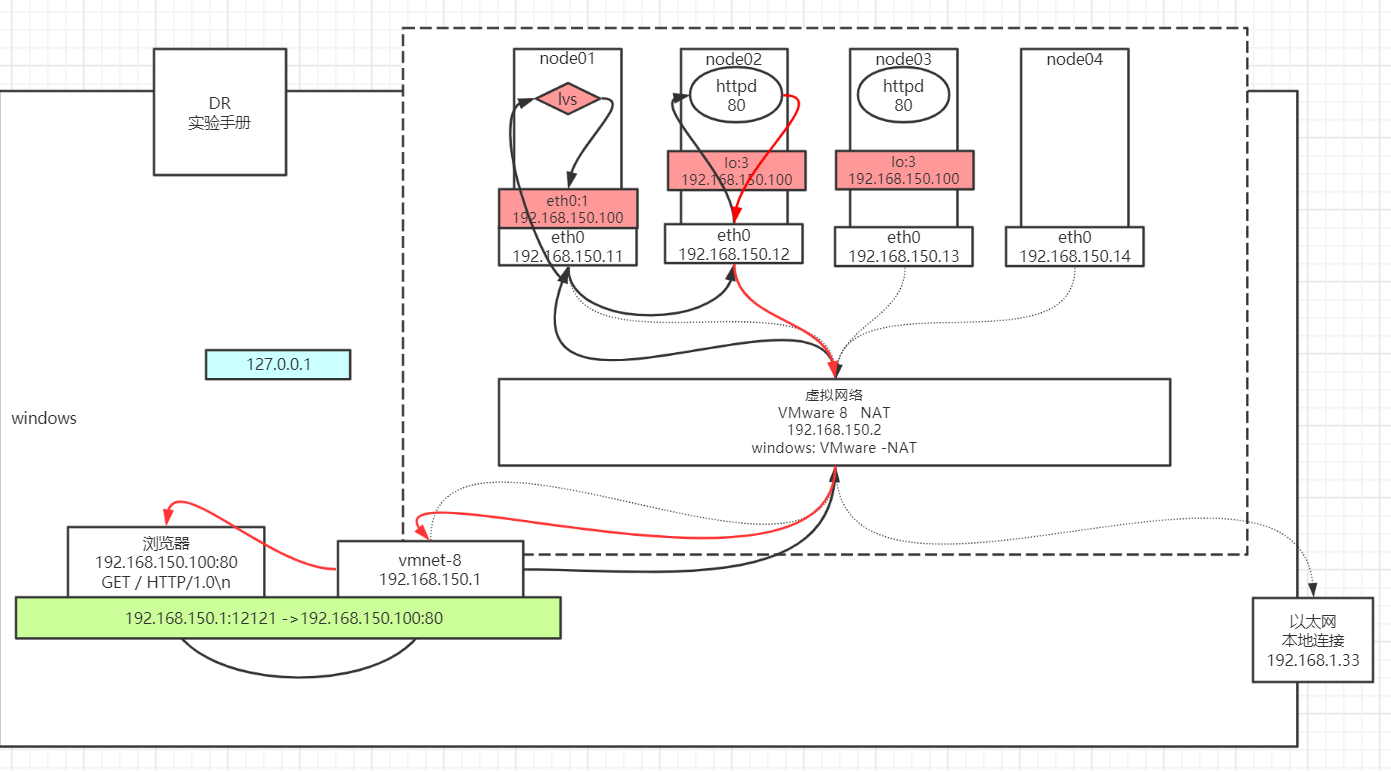
node01: ifconfig eth0:8 192.168.150.100/24node02~node03: 1)修改内核: echo 1 > /proc/sys/net/ipv4/conf/eth0/arp_ignore echo 1 > /proc/sys/net/ipv4/conf/all/arp_ignore echo 2 > /proc/sys/net/ipv4/conf/eth0/arp_announce echo 2 > /proc/sys/net/ipv4/conf/all/arp_announce 2)设置隐藏的vip: ifconfig lo:3 192.168.150.100 netmask 255.255.255.255 RS中的服务:node02~node03: yum install httpd -y service httpd start vi /var/www/html/index.html from 192.168.150.1xLVS服务配置node01: yum install ipvsadm ipvsadm -A -t 192.168.150.100:80 -s rr ipvsadm -a -t 192.168.150.100:80 -r 192.168.150.12 -g -w 1 ipvsadm -a -t 192.168.150.100:80 -r 192.168.150.13 -g -w 1 ipvsadm -ln验证: 浏览器访问 192.168.150.100 看到负载 疯狂F5 node01: netstat -natp 结论看不到socket连接 node02~node03: netstat -natp 结论看到很多的socket连接 node01: ipvsadm -lnc 查看偷窥记录本 TCP 00:57 FIN_WAIT 192.168.150.1:51587 192.168.150.100:80 192.168.150.12:80 FIN_WAIT: 连接过,偷窥了所有的包 SYN_RECV: 基本上lvs都记录了,证明lvs没事,一定是后边网络层出问题问题:
- LVS可能会发生单点故障
- 主备
- RS挂的话,部分请求会失败
keepalived
作为一个通用工具,解决高可用问题
配置
vrrp_instance VI_1 { state MASTER // 备服务器BACKUP interface eth0 virtual_router_id 51 priority 100 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 172.17.0.100/16 dev eth0 label eth0:3 }}virtual_server 172.17.0.100 80 { delay_loop 6 lb_algo rr lb_kind DR nat_mask 255.255.255.0 persistence_timeout 0 protocol TCP real_server 172.17.0.4 80 { weight 1 HTTP_GET { url { path / status_code 200 } connect_timeout 3 nb_get_retry 3 delay_before_retry 3 } } real_server 172.17.0.6 80 { weight 1 HTTP_GET { url { path / status_code 200 } connect_timeout 3 nb_get_retry 3 delay_before_retry 3 } }}